1 min to read
데이터 수집 및 전처리
빅데이터 분석 절차, 데이터 수집, package pandas

데이터 분석 절차
- 데이터 수집 (Data Collection)
- 데이터 전처리 (Data Preprocessing)
- 모델 선택 (Model Selection)
- 평가 및 적용 (Evaluation & Application)
실습 예제
-
타이타닉 탑승자 데이터 파일 다운로드 : https://www.kaggle.com/c/titanic/data
-
데이터 확인 (메모장으로 파일 열어보기) : 콤마(,)로 열 구분 / 엔터키로 행 구분 보통 첫번째 행에는 변수명(컬럼명)이 옴
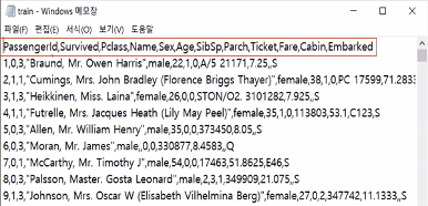

데이터 수집 기술이 발전하고 네트워킹 속도도 발전하다 보니 대기업 한 부서에서 관리하는 데이터가 약 몇십만개 행이 됨. 이렇게 많은 데이터들은 엑셀로 열리지 않아 파이썬을 가지고 활용하여 데이터를 불러옴 -> 나에게 필요한 몇 천개 정도만 뽑아서 사용 (대기업에서는 엑셀이 코딩으로 대체되고 있음)
라이브러리 pandas
학습 파일 불러오기
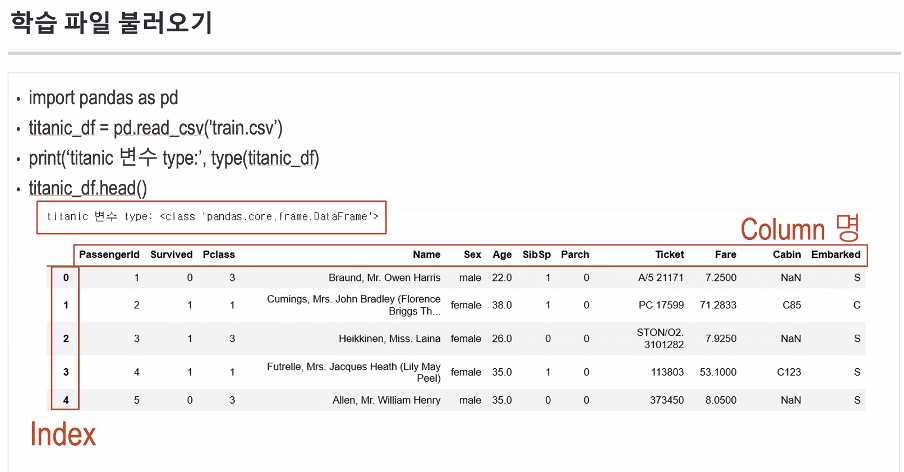
- 데이터를 표로 만들기 위해 pandas라는 라이브러리 사용
drop 삭제, 추가, 검색 등의 함수 사용함 / null값을 없애지 않으면 연산이 되지 않음 등
- DataFrame : 행과 열이 존재하는 표
- column 하나밖에 없으면 Series
학습 데이터 정보 출력
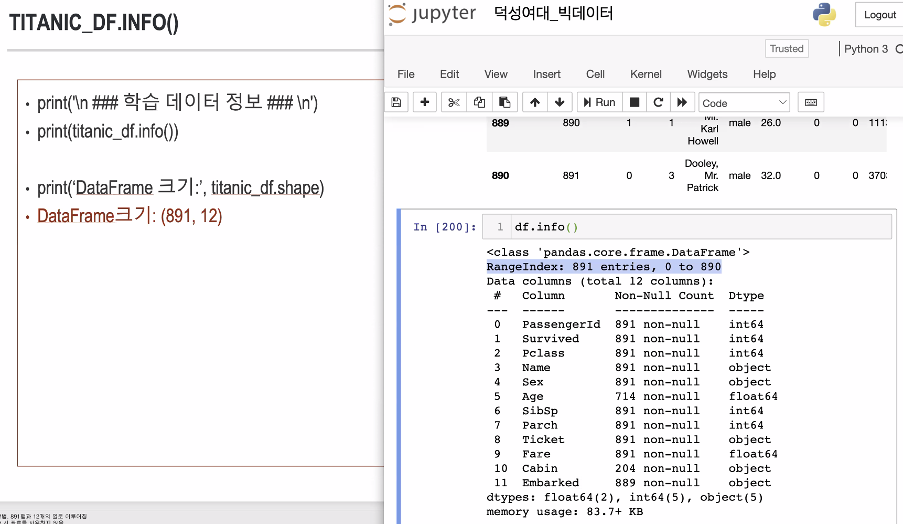
- 데이터의 개수 (=행의 개수) : 891개
- 한 데이터가 가지고 있는 속성 (=열의 개수): 12개
데이터 프레임 기타 정보 확인
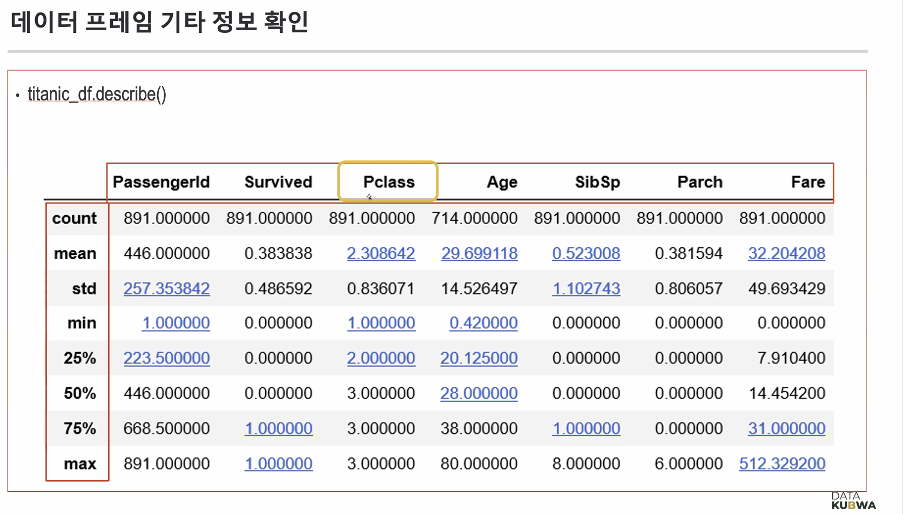
숫자데이터가 어떻게 분포되어 있는지 볼 수 있음
columns 12개 중에 7개만 나옴 -> 이유 ? 통계값이므로 값이 숫자인 값들만 나옴
- mean : 평균값
- std : 숫자가 클수록 평균에서 더 멀음 (표준편차)
- min, max : 최솟값, 최댓값
- 50% : 중앙값
- 25%, 75% : 상위 25%, 상위 75%
PCLASS 분포값 확인


Comments